10 Most-used Cheminformatics Databases for the Biopharma Industry in 2025
Explore the best 10 cheminformatics databases ranked by their usage within the scientific community.
6 min read
March 20th, 2025
Last updated: March 21st, 2025


Introduction
Cheminformatics databases offer crucial insights into chemical structures, properties, and biological activities. They support researchers in developing new therapeutics, identifying novel drug candidates, predicting toxicity, and modeling molecular interactions.
This blog explores the most widely used cheminformatics databases, highlighting how they contribute to biopharmaceutical research. The impact of these databases is evident from their frequent citations in scientific research, underscoring their value in biopharma. This ranking is built on that citation data, ensuring we highlight the most widely used and trusted resources. Updated details on key factors such as data volume, curation quality, and practical applications have been highlighted to build a meaningful list.
Read on to explore the most widely used cheminformatics databases supporting biopharma research.
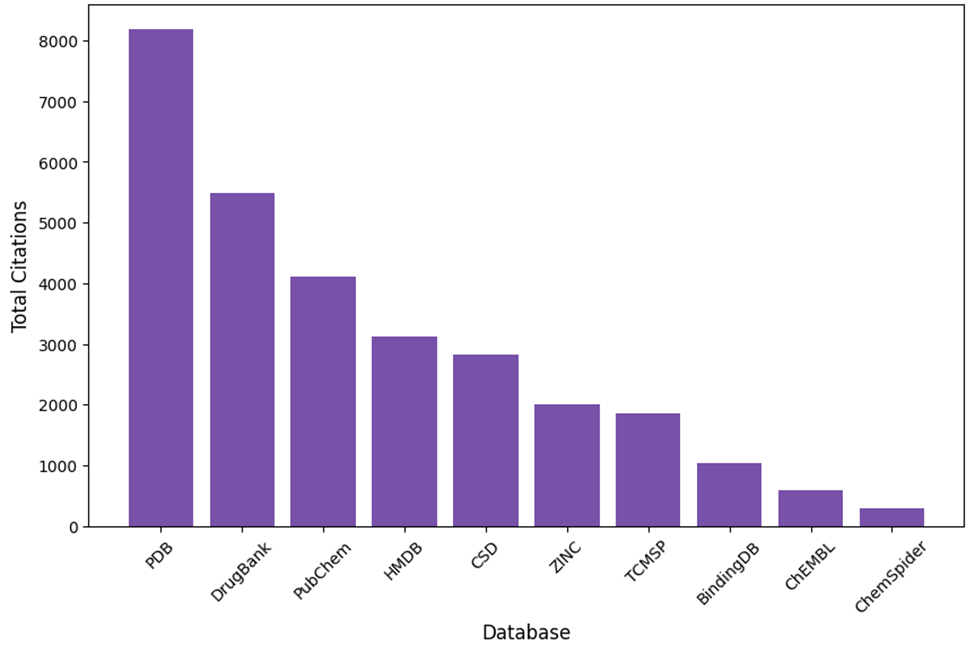
Top 10 cheminformatics databases ranked by citation count (2023–2025)
1. Protein Data Bank
The Protein Data Bank (PDB) contains 3D structures of protein, nucleic acids, and other macromolecules, with over 227,000 structures, determined by X-ray crystallography, NMR, and cryo-EM.
| Atrributes | Statistics |
|---|---|
| Citations: | 8,194 |
| Coverage: | Niche (227,000+ 3D Structures of proteins, nucleic acids, and complexes) |
| Curation: | Mostly manual (Submitted by authors) |
| Access: | Free and publicly available |
PDB is a cheminformatics database that provides detailed atomic coordinates, structural validation tools, and visualization resources for studying biomolecular interactions and functions. In the biopharma industry, it is primarily used for structure-based drug design, understanding molecular interactions, and protein engineering, which are essential for developing targeted therapies. As the primary source for macromolecular structures, the PDB is fundamental for diverse biopharma applications, making it impactful beyond just the field of chemistry.
PDB Database Interface
2. DrugBank
DrugBank is a database of FDA-approved and experimental drugs, including their targets, mechanisms, and pharmacokinetics, with over 17,000 drug entries and 5,000 protein targets.
| Atrributes | Statistics |
|---|---|
| Citations: | 5,479 |
| Coverage: | Niche (17,000+ drugs (approved/ experimental), pharmacokinetics, target pathways) |
| Curation: | Hybrid (manually validated + automated updates) |
| Access: | Free and publicly available for non-commercial use |
DrugBank is an invaluable resource in the field of drug development, ADMET prediction, and pharmacovigilance. Its comprehensive database links drugs to their corresponding targets, enzymes, and clinical trial data, providing researchers with a detailed insight into the pharmacological profiles and real-world applications of each compound.
DrugBank Interface showing search results for Acetaminophen
Want to learn more about how researchers applied cheminformatics data in drug discovery?
3. PubChem
PubChem is a freely accessible repository maintained by the NCBI that contains millions of chemical structures, bioassay results, and related biological activities. It serves as a central resource for both academic and industrial research.
| Atrributes | Statistics |
|---|---|
| Citations: | 4,111 |
| Coverage: | Broad ( 119 Million+ compounds, bioassays, toxicity data, and chemical properties) |
| Curation: | Hybrid (crowdsourced and automated data integration with manual oversight) |
| Access: | Free and publicly available |
The database is highly useful for high-throughput screening, toxicity prediction, and drug repurposing, and it stands out as the largest free chemical repository available, integrating extensive datasets from agencies such as the NIH and EPA.
PubChem Database Interface
4. Human Metabolome Database
The Human Metabolome Database (HMDB) is a comprehensive database that contains detailed information about small molecule metabolites found in the human body. This information includes their chemical, clinical, and biological properties. The database contains over 220,000 metabolite entries, as well as their structures, biological roles, and spectral data.
| Atrributes | Statistics |
|---|---|
| Citations: | 3,131 |
| Coverage: | Niche (220,000+ metabolites with spectral, clinical, and biochemical data) |
| Curation: | Hybrid (automated data extraction + manual expert review) |
| Access: | Free and publicly available |
HMDB is the largest repository of human metabolomics data. It is used in the biopharmaceutical sector for metabolomics research, biomarker discovery, and understanding human metabolism and disease mechanisms, especially for personalized medicine. Its unique features include comprehensive data on the human metabolome and spectral data for metabolite identification. HMDB also links diseases and metabolites, making it valuable for biomarker discovery and metabolic pathway analysis.
 HMDB Database Interface
HMDB Database Interface
Looking for the best resources to work on the vast chemical data from public repositories?
Explore our curated collection of cheminformatics software and tools!
5. Cambridge Structural Database
The Cambridge Structural Database contains 3D structures of small molecules determined by X-ray crystallography, with over 1.24 million entries, focusing on organic and metal-organic compounds.
| Atrributes | Statistics |
|---|---|
| Citations: | 2,820 |
| Coverage: | Niche (1.24 Million+ small-molecule crystal structures) |
| Curation: | Manual (experimental validation via X-ray/neutron diffraction) |
| Access: | Paid subscription |
It is the gold standard for 3D structural data, offering unique features such as comprehensive small molecule crystal structures essential for materials science and drug discovery, with tools for analyzing structural data. Its primary use in the biopharma industry lies in understanding molecular geometry, crystal packing, and intermolecular interactions, which are crucial for drug design, particularly in optimizing compound stability and solubility. The CSD is also useful for crystal engineering, polymorphism studies, and ligand geometry analysis.
6. ZINC
ZINC is a database of over 54 billion compounds, among which over 5 billion providing 3D structures for virtual screening, focusing on commercially available options for drug discovery.
| Atrributes | Statistics |
|---|---|
| Citations: | 1,997 |
| Coverage: | Niche (54 Billion+ commercially available compounds) |
| Curation: | Automated (vendor catalogs + standardized formats) |
| Access: | Free and publicly available |
It is a free database. The latest version, ZINC-22, represents a significant update, expanding the database to 54.9 billion molecules, 5.9 billion of which have been built in biologically relevant ready-to-dock 3D formats. This database is primarily used in the biopharma industry to streamline early drug discovery processes through high throughput virtual screening to identify potential lead compounds. ZINC is pre-filtered for drug-like properties and also has 3D conformers available, which makes it particularly useful for virtual screening, hit identification and lead optimization.
ZINC22 Database Interface
7. Traditional Chinese Medicine Systems Pharmacology
The Traditional Chinese Medicine Systems Pharmacology Database (TCMSP) provides information on compounds from traditional Chinese medicine, their targets, and bioactivities, with over 500 compounds and 30,000 target interactions.
| Atrributes | Statistics |
|---|---|
| Citations: | 1,850 |
| Coverage: | Niche (500+ herbal medicines; 30,000+ compounds with ADMET properties) |
| Curation: | Manual (literature mining + experimental validation) |
| Access: | Free and publicly available |
TCMSP is a valuable tool for herbal medicine research, offering pharmacological data and enabling multi-target drug discovery. It facilitates toxicity prediction through absorption, distribution, metabolism, excretion, toxicity (ADMET) properties and uniquely integrates traditional Chinese medicine with systems pharmacology. By linking compounds, targets, and diseases, it provides a holistic view of herbal medicine interactions and supports network-based analyses.
TCMSP Database Interface
8. BindingDB
BindingDB, a publicly accessible database, comprises 3 million+ binding data entries for over 1.3 million compounds and 9,500 targets. Serving as a valuable resource for comprehending molecular interactions and facilitating computational docking studies, it furnishes binding affinities for protein-ligand complexes, gleaned from published literature.
| Atrributes | Statistics |
|---|---|
| Citations: | 1,045 |
| Coverage: | Niche (3 Million+ protein-ligand binding affinities (Kd, Ki, IC50)) |
| Curation: | Hybrid (manual + automated data extraction) |
| Access: | Free and publicly available |
It is a database focused on protein-small molecule interactions. It's used for binding affinity prediction and target validation in drug design. Its unique features include quantitative interaction data for structure-activity modeling, and it is primarily used in the biopharmaceutical industry for QSAR modeling, docking studies, and understanding ligand-receptor interactions.
The BindingDB Interface
Are you a medicinal chemist yet to explore cheminformatics?
Here are five compelling reasons to take the plunge!
9. ChEMBL
ChEMBL is a database of bioactive molecules with their activities against various targets, curated from scientific literature. It contains over 2.4 million compounds and 20.3 million bioactivity measurements focusing on drug-like molecules.
Citations : 586
Coverage: Broad
2.4 Million+ bioactive molecules, drug-target interactions, SAR data
Curation :Manual (expert-curated from literature/ patents)
Access : Free and publicly available
| Atrributes | Statistics |
|---|---|
| Citations: | 1,045 |
| Coverage: | Niche (3 Million+ protein-ligand binding affinities (Kd, Ki, IC50)) |
| Curation: | Hybrid (manual + automated data extraction) |
| Access: | Free and publicly available |
This database is a vital resource for drug discovery, target identification, and polypharmacology studies, offering a unique focus on quantitative bioactivity data—such as IC50 and Ki values—for detailed analysis of compound potency and efficacy in rational drug design. With multiple access methods, including a web interface, RDF distribution, and RESTful web services, it ensures seamless data retrieval, while recent updates, such as natural product-likeness scores and chemical probe annotations, further enhance its usability in pharmacology and related research.
ChEMBL Database Interface
10. ChemSpider
ChemSpider is a free chemical structure database provided by the Royal Society of Chemistry (RSC) that aggregates data from hundreds of sources, offering access to chemical structures, properties, spectra, and links to literature.
Citations : 292
Coverage: Broad
130 Million+ chemicals from >500 sources (patents, journals, vendors)
Curation : Hybrid (automated aggregation + community curation)
Access : Free and publicly available
It is a powerful tool for chemical structure verification and property prediction, backed by the RSC and integrated with other RSC resources—making it indispensable in biopharma for identifying and evaluating compounds in early research stages.

ChemSpider Database Interface
Looking for the best resources to work on the vast chemical data from public repositories?
Explore our curated collection of cheminformatics software and tools!
Conclusion
Cheminformatics databases have become indispensable resources in the biopharma industry. From structure-based design using PDB to virtual screening with ZINC and metabolomics research with HMDB, these databases serve diverse yet interconnected roles in modern pharmaceutical science.
Looking ahead, we can expect advancements in AI-driven cheminformatics, deeper integration of machine learning for predictive modeling, and enhanced data interoperability across multiple platforms. Open-access initiatives and the continuous expansion of these databases will further empower researchers, making cheminformatics an even more powerful domain in biopharmaceutical research.
Cheminformatics is a highly sought-after skill in modern drug discovery.
Neovarsity's cheminformatics certification course teaches the end-to-end implementation of cheminformatics tools and its applications in drug discovery and development. It offers:
- Hands-on training in RDKit, KNIME, and QSAR modeling
- Real-world projects which includes building molecular graphs, screening chemical libraries
- Career boost: Work in computational chemistry, biotech AI, or pharma R&D